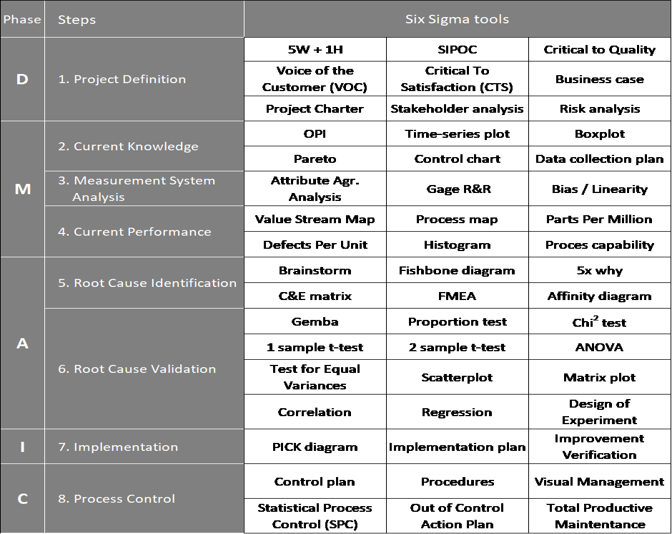
Does the decision that you want to live a fuller but shorter life or a more restricted but longer life reside with you or your doctor? Eric Topol in his excellent book the ‘Patient will see you now’ talks about how you should become CEOs of your own health journeys, instructing reports and procedures as required to drive your own life outcomes. However we need data to make informed decisions about the lifestyles, medications and medical procedures we want to undertake. No one should care about this more than you and while most clinicians are undoubtably trying to do the best they can by you, they don’t have the full picture and are using general data to advise you. They may know more than you about a particular scenario but they don’t know what is best for you. They are the COOs monitoring the operations of the body reporting back to you regularly so you can decide the best way forward.
Is it so surprising people lie to their Doctor?
The lifestyle changes proposed by my GP (Doctor): no booze, no spicy food, no coffee and even no chocolate seemed like a complete attack on my way of life so I opted for privately funded surgery which has stopped the acid in my stomach boiling up to burn my oesophagus and corrode my gums. For the first time in over a year I am sleeping the whole night through and no longer coughing every 5 minutes. Gastroesophageal reflux disease (GERD) is incredibly common and has had a real impact on my work and family life over this past year as it has become more acute.
I am now a week into my recovery from the keyhole surgery I had to stop the GERD. The first thing I noticed on waking from surgery was pain in my shoulders caused by the trapped carbon dioxide they used to inflate my abdomen so they had room to move my innards around and do the necessaries. It took around 4 days perhaps more to dissipate but was completely manageable with paracetamol. The second thing I noticed was that I couldn’t burp and when I needed to it hurt then turned into flatulence. The surgery has created a one way valve to the entrance of my stomach which stops acid getting out but also makes puking and burping painful and potentially damaging to the newly created valve. My mum is delighted about the belching situation but my wife and work colleagues are less so around the flatulence! For most people this becomes less of an issue overtime as the surgery beds in and loosens but that remains to be seen in my case.
The recovery thus far has been remarkably quick and I need to be careful that I don’t do too much too quickly. I still have 5 weeks to go and my diet will progress from liquid, to puree, to soft. The medical advice on this is varied: Americans and those in the north of England seem to be able to move through these stages faster than people in London where I am who have 2 weeks liquid, 2 weeks puree, 2 weeks soft. I have had a week of liquid and I am moving on to puree because I have an American mother and my sister lives in the North. It is also because I have tried and it seems ok – I am not going to force anything but the 2,2,2 week rule seems arbitrary or at least based on worst case scenarios for people older than me.
How I would like to make medical decisions
Going back in time to when I decided to have this procedure I could definitely have been more data driven. My gastroenterologist arrived shortly after the fentanyl had worn off post endoscopy where he had found my hiatus hernia. I hadn’t had any food for 8 hours and there was a plate of food in front of me. I was high and hungry as he explained what he had found and said I should consider fundoplication. That was pretty much all there was on the Gastroscopy report too. If I had my time again I would have asked the following questions and perhaps booked another consultation with him:
- What do similar patients to me usually ask at this stage?
- What are the alternatives to this course of action?
- If you were me who else would you speak too?
- Where can I find more information about each of the options?
The information I wanted I got from the following form created by Digital consent | Concentric Health an hour before the surgery. My research would have gone much more easily if I had this information weeks before:



Here are the questions I will ask of future consultants about any procedure:
- What are the immediate risks during or shortly after surgery?
- What are the early risks in the days after surgery?
- What are the late risks in the months and years after surgery?
- What are the odds on those risks?
- Where did the data come from for those calculations?
- What assumptions have been made in those calculations?
Graphical Information System (GIS) Mapping for my Health Data
GERD is a chronic disease that the surgery will help with for 8 to10 years with a good wind behind me so to speak! Unfortunately it will probably not be my last chronic condition and I would like to build a more precise picture of my health so I can make better informed decisions as my health becomes more complicated. My devices like Fitbit, phone and ring are tracking a lot of information about my lifestyle, my genome has been sequenced by the research charity About us – Our Future Health. How can I use this data with my medical record? Could some of it be useful to my future consultants? How can I collate information from my NHS and Private Health sources?
Eric Topol a cardiologist talks about creating maps that overlay demographic, physiologic, anatomic, genomic, biological and environmental information on top of your medical record similar to how Google can overlay different types of data on top of a geographic map like traffic, satellite and street views etc. He calls it a 10 by 10 womb to tomb data approach, 10 key data points at 10 milestones in life. Although probably the wrong phrase for it there is no killer app for storing and visualising our health data. Amazon, Oracle, Fitbit and others want to store your information for you their way but if history teaches anything about big tech it is that they do not prioritise interoperability. I would prefer to own the data and store it in a universal format that tech companies can plug their apps into. I will happily pay them for an app that visualises my data, but if it doesn’t work for me I would like to stop using their app and try another. That is not possible if all my data is locked in the Fitbit walled garden, I may be able to export the data but then I will need to clean it for import into the next walled garden.
Tim Berners Lee father of the web has a company that has been trying to solve this problem, not just for health but for the internet in general. His company Inrupt uses an open standard he developed called Solid to create ‘wallets’ that provide a secure, decentralised way for individuals to exchange public and private data. These wallets could be stored on a server in your house, at your company, in Amazon, Azure, GCP et al. For this to work lots of people need to start using these wallets so the network effects mean that developers and big tech feel the need to develop infrastructure and apps that work with the standard rather than each insisting on using their own.
Inrupt’s strategy to make this happen is to work with large organisations, like governments, hospitals and PLCs to help them develop these wallets for their end users. In Belgium citizens can store official documents like education diplomas in an Inrupt wallet, the individual can then decide if they want to share them with companies they want to work for, the government or whoever. Once the wallet is created and people are used to using them they can store other things too like health information. If you don’t want to store all your information on a government or private company server you can move / copy it to another location as it is an open standard, hopefully smart companies will be created to help make this easier if the incentive is great enough.
Realistically this is still a long way away and who knows which technologies will win in the dawdle to deliver this incredibly useful but largely unprofitable functionality. For non-profits and commercial enterprises alike the barriers to entry are significant but that hasn’t stopped me being more organised around my health data. When I asked my GP what my blood type I am, they consulted almost 50 years worth of my medical data and couldn’t tell me. I now have that information after I made a Subject Access Request for the blood tests I had at the hospital before my operation.
Conclusion
The surgery I opted for has trade-offs, I can’t live life as large as I could before but I can sleep better at night albeit with a lot more flatulence. I could perhaps have achieved a similar effect with more drugs and more severe lifestyle changes but this was my decision in spite of pressures on the NHS and the GPs thoughts on hedonism. Thinking about these risks and probabilities will be useful when I have to make more serious medical decisions. Often the path is not clear and the ‘right’ answer depends on the risks you want to take on given a set of realistic outcomes you want to achieve.
At almost 50 years old I have decided to become CEO of my own health. There are many decisions to come that I am not happy to leave completely to very busy professionals who don’t have the full facts and are influenced by a wealth of conscious and unconscious biases. Eliot Freidson in the Profession of Medicine argues that professions should have autonomy to make decisions that are technical, but they should not make decisions in areas where they do not have expertise, and that on moral or evaluative questions lay people should have as same involvement in decision making as experts.
While health services are acknowledging some of this and ‘no decision about you without out you’ approaches are bedding in it is still surprisingly difficult, baffling and combative to get your medical records and assess reliable information about future treatments yourself so you can use it in a meaningful way. Dr Google and its AI friends often create more questions than they answer but that doesn’t mean you shouldn’t try and it is never too early to think more about your health.
References
- Eric Topol – The Patient Will See You Now
- Concentric Health patient consent forms – https://concentric.health/
- Inrupt – https://www.inrupt.com/case-study/flanders-strengthens-trusted-data-economy
- Eliot Freidson – The Profession of Medicine https://en.wikipedia.org/wiki/Profession_of_Medicine